演示文稿 - Can Large Language Models Credibly Stand in for Humans in Game-Theoretic Experiments?
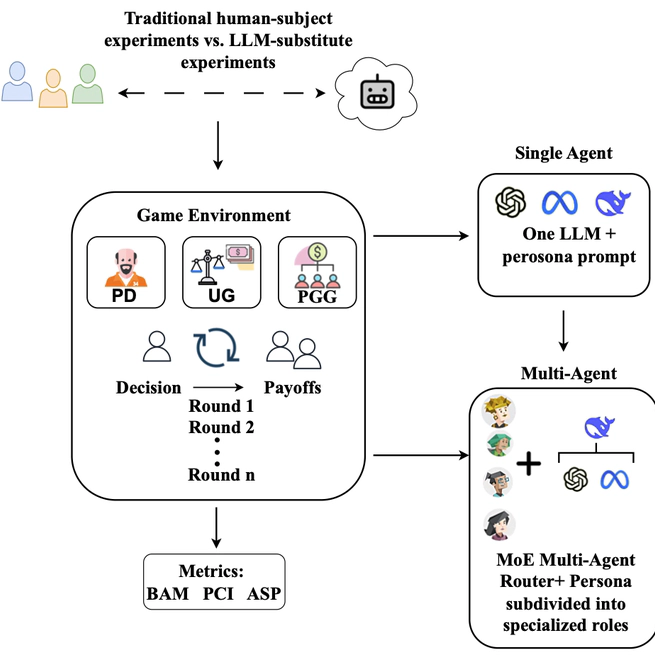
评估 LLMs(如 GPT-4o、LLaMA-3.3)在经典博弈中的表现,包括 Prisoner’s Dilemma、Ultimatum Game 和 Public Goods Game。 我们提出了一种多智能体路由框架 PRIME-Router,可在重复交互中提升策略适应性和角色一致性。
5月 21, 2025
Can Large Language Models Credibly Stand in for Humans in Game-Theoretic Experiments?
评估了 LLM 在策略性社会博弈中与人类行为的一致性,并提出 PRIME-Router 以增强角色一致性和适应性。
4月 17, 2025