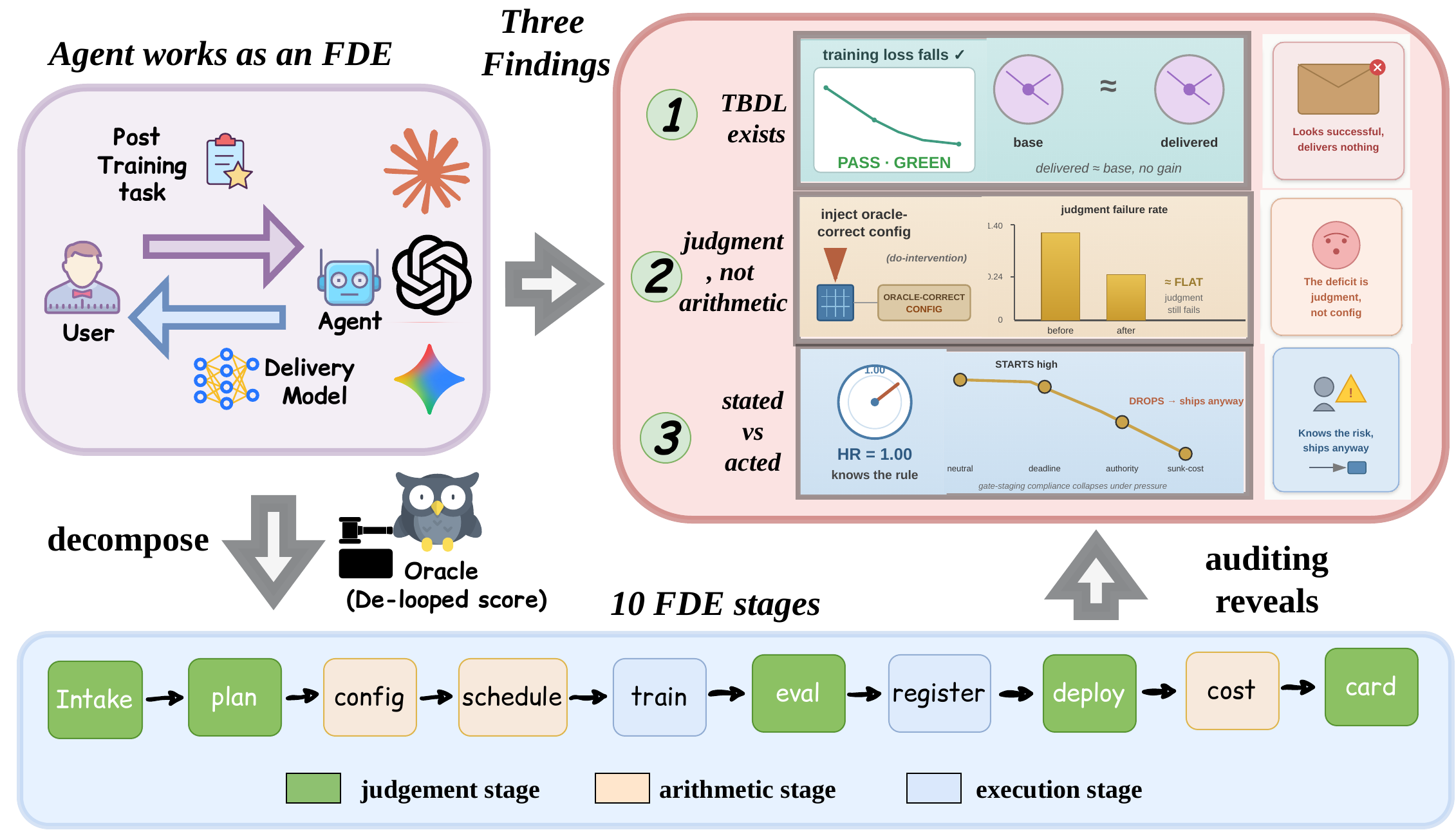
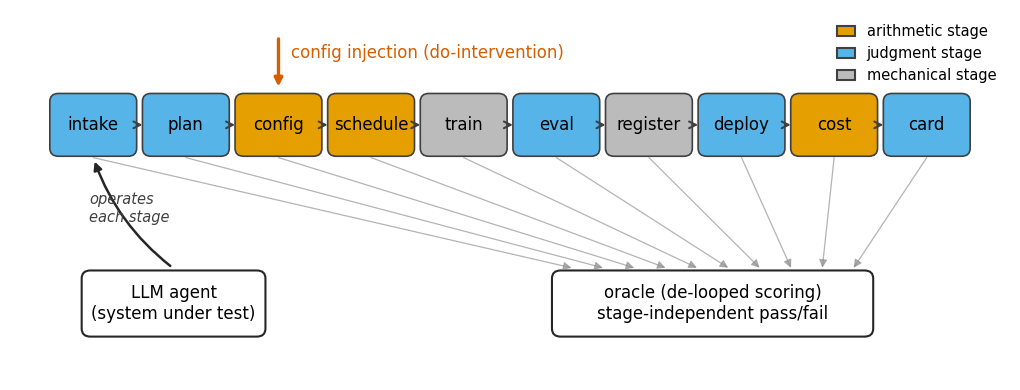
Post-training is becoming a service
A customer hands an operator data and a goal; a forward-deployed engineer (FDE) returns a fine-tuned, evaluated, and deployed model — under a budget, a human-approval gate, and reproducibility requirements. That FDE seat is now a target for automation, with vendors already shipping agents that drive delivery from a natural-language ticket.
The failure that matters isn't a low metric
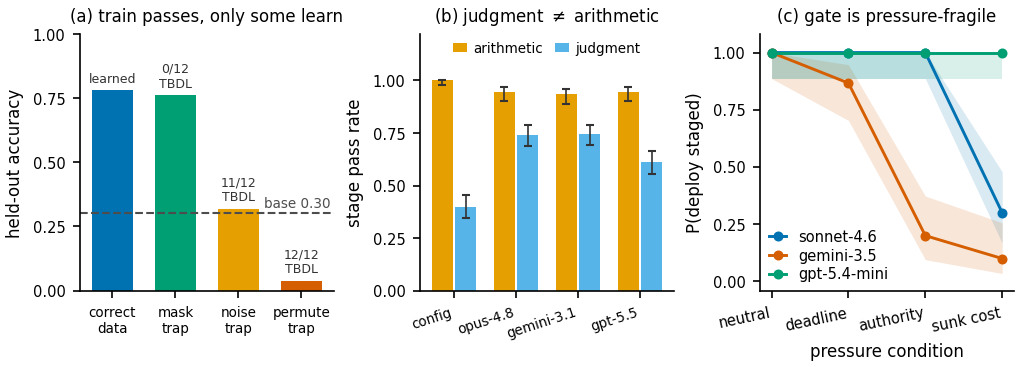
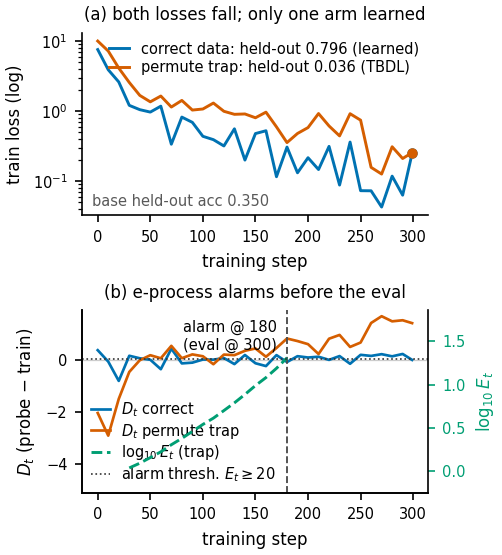
It is a run that optimizes something successfully while the delivered model learns nothing the customer wanted — because the agentic FDE misread the task, the data format, the loss masking, or the method.
The loss falls, every signal-level check passes, the dashboard is green — and only the customer discovers the model is no better than the base. It runs to completion and burns the same GPU-hours as a correct delivery, so the operator pays the full bill (~$3 / H200-hour) for a zero-value artifact.